
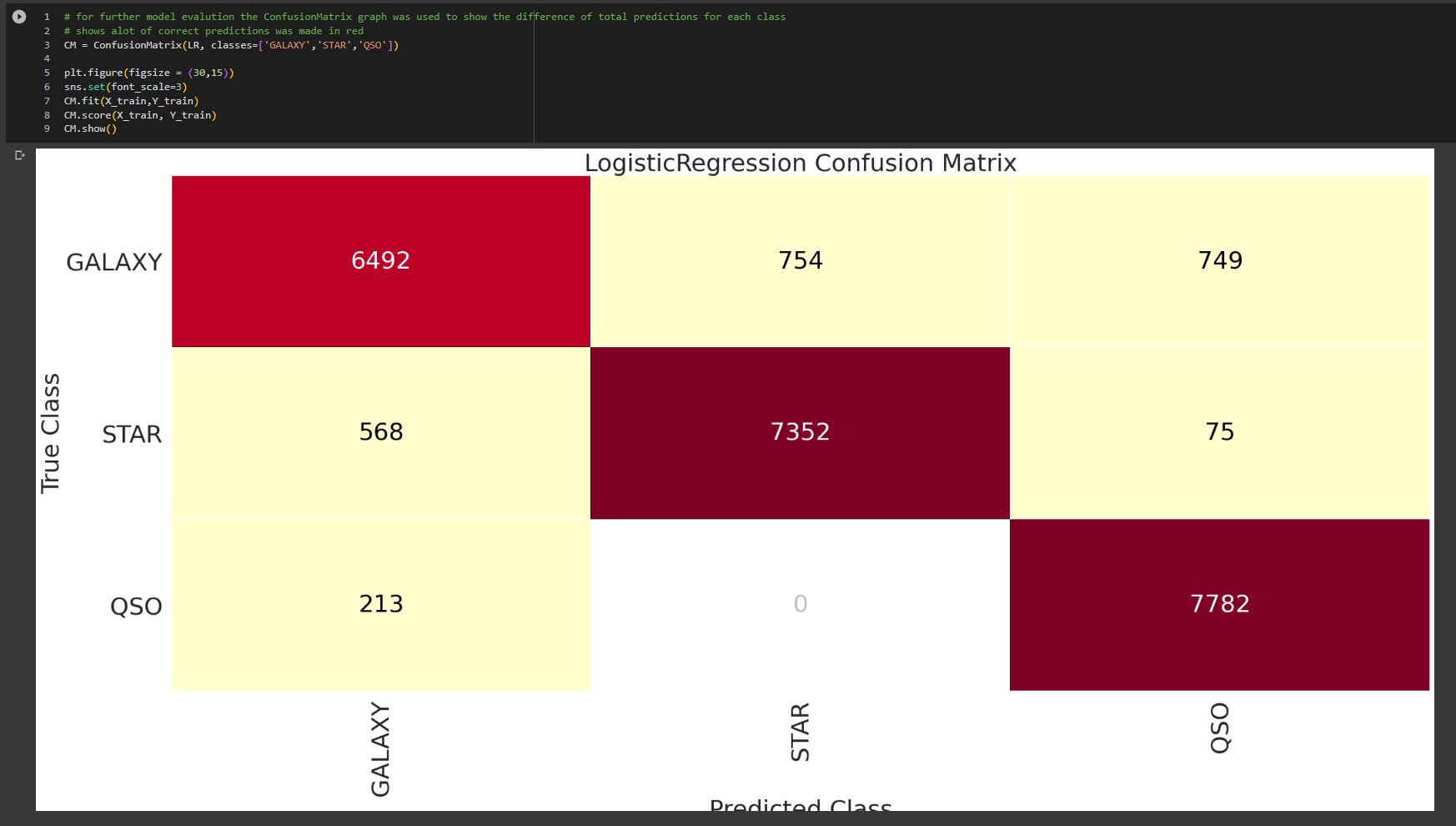
This project was created at my University for my Artificial Intelligence and Machine Learning module, where I collaborated with a team of four members to create supervised machine learning algorithms for predicting spectral classes based on a given dataset. Each team member was responsible for developing a distinct algorithm model suited to our dataset. I chose to implement a logistic regression algorithm for this purpose. We used Python, along with libraries such as Scikit-learn for machine learning, Pandas for data manipulation, and Seaborn/Matplotlib for data visualization. Our dataset comprised 17 features and 100,000 observations, representing real-world data related to stellar classification. The goal was to predict the spectral class of each observation, which could be one of three possibilities: star, galaxy, or quasar. One of the 17 features served as the target variable for this supervised multiclass classification problem, establishing the ground truth for our models. We aimed to build and compare four different classification models to accurately predict the spectral class of each observation. Overall, it took the team around 2 months to complete as we had to also make a report with the algorithm. It was a very interesting and fun project. From it, I learned many new topics throughout this module involving Machine Learning with developing a supervised classification algorithm being logistic regression using libraries such as pandas, NumPy, and Scikit-Learn. As well as comparing it with other developed classification algorithms with graph visualization using libraries such as Matplotlib, Seaborn, and Yellowbrick.
features
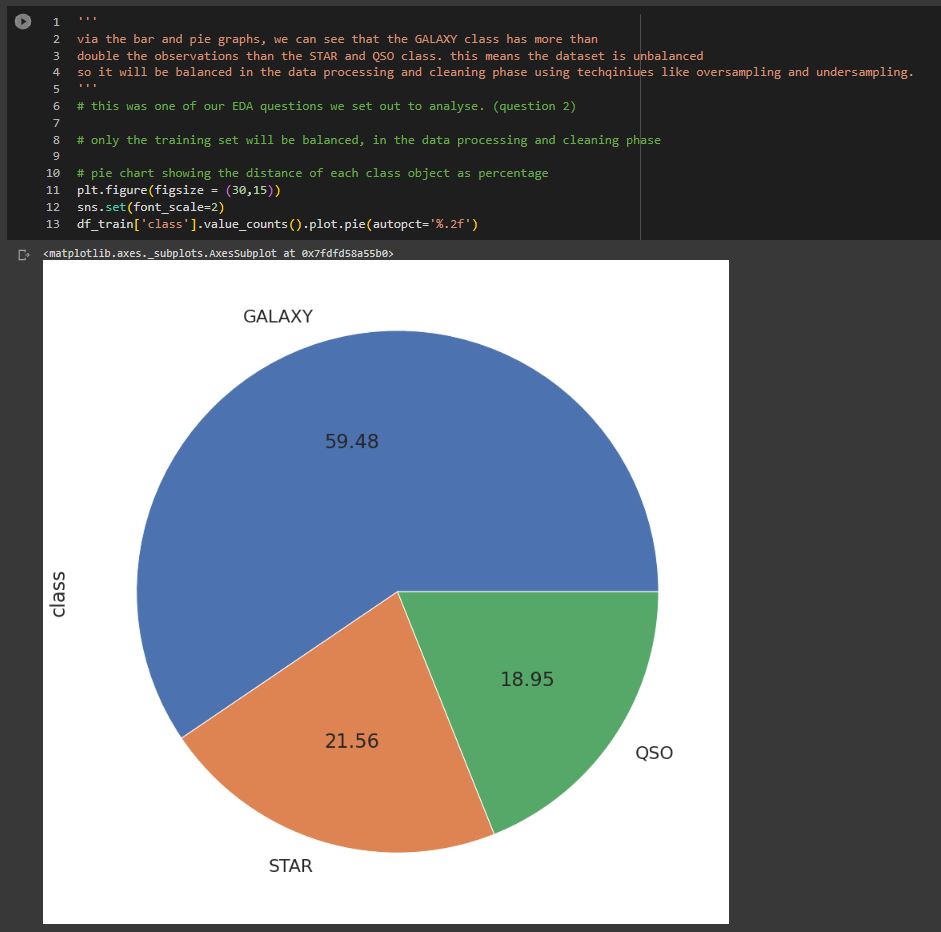
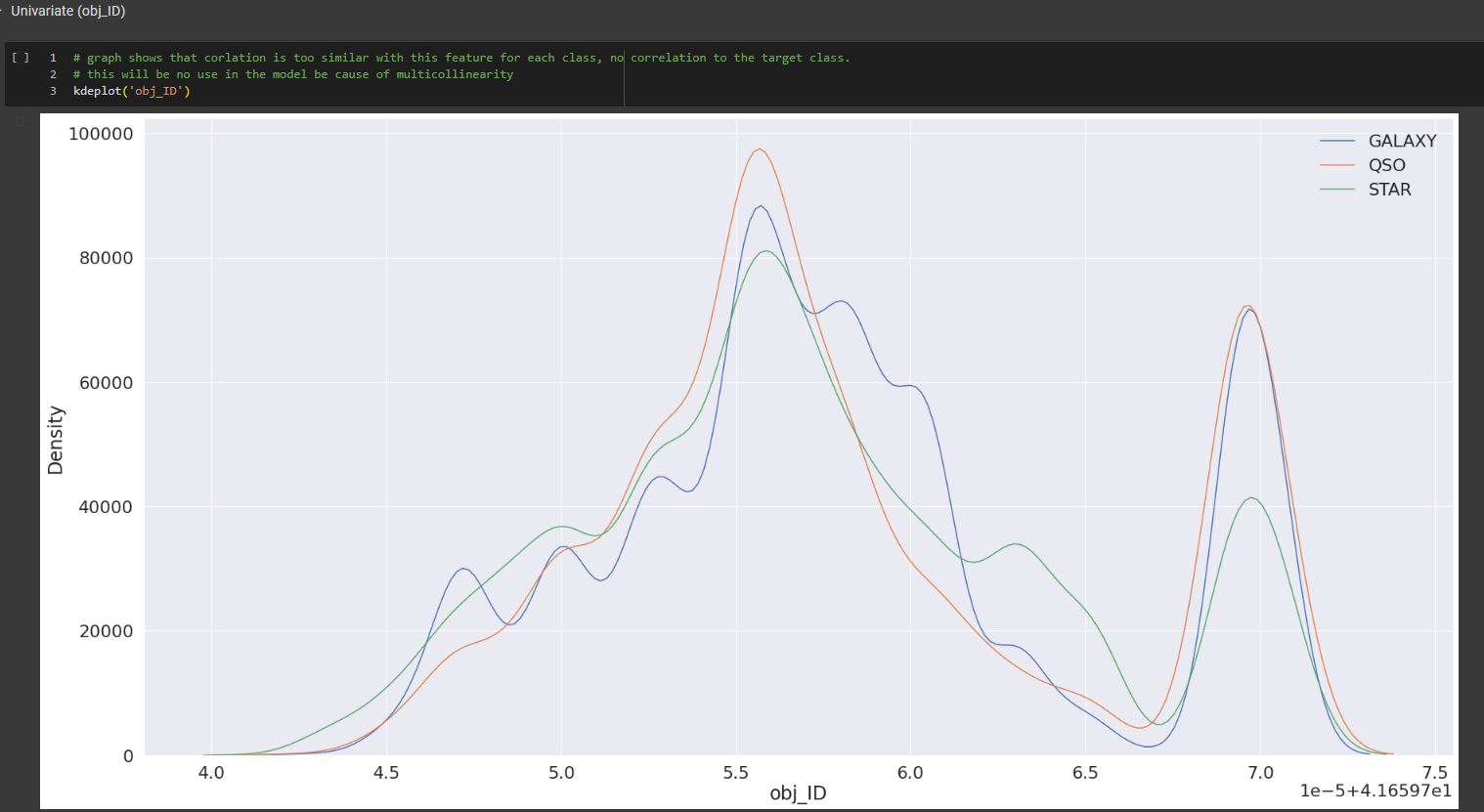
- Algorithm was trained on a dataset which contains 17 features and 100,000 observations that represent real-world data for the concept of stellar classification where a spectral class is determined based on its characteristics.
- The ata pre-processing phase involved feature selection, data cleaning, data encoding, data scaling and data transformation.
- Techniques used involved random under sampling, normalization, IQR, feature dropping and dataset splitting.
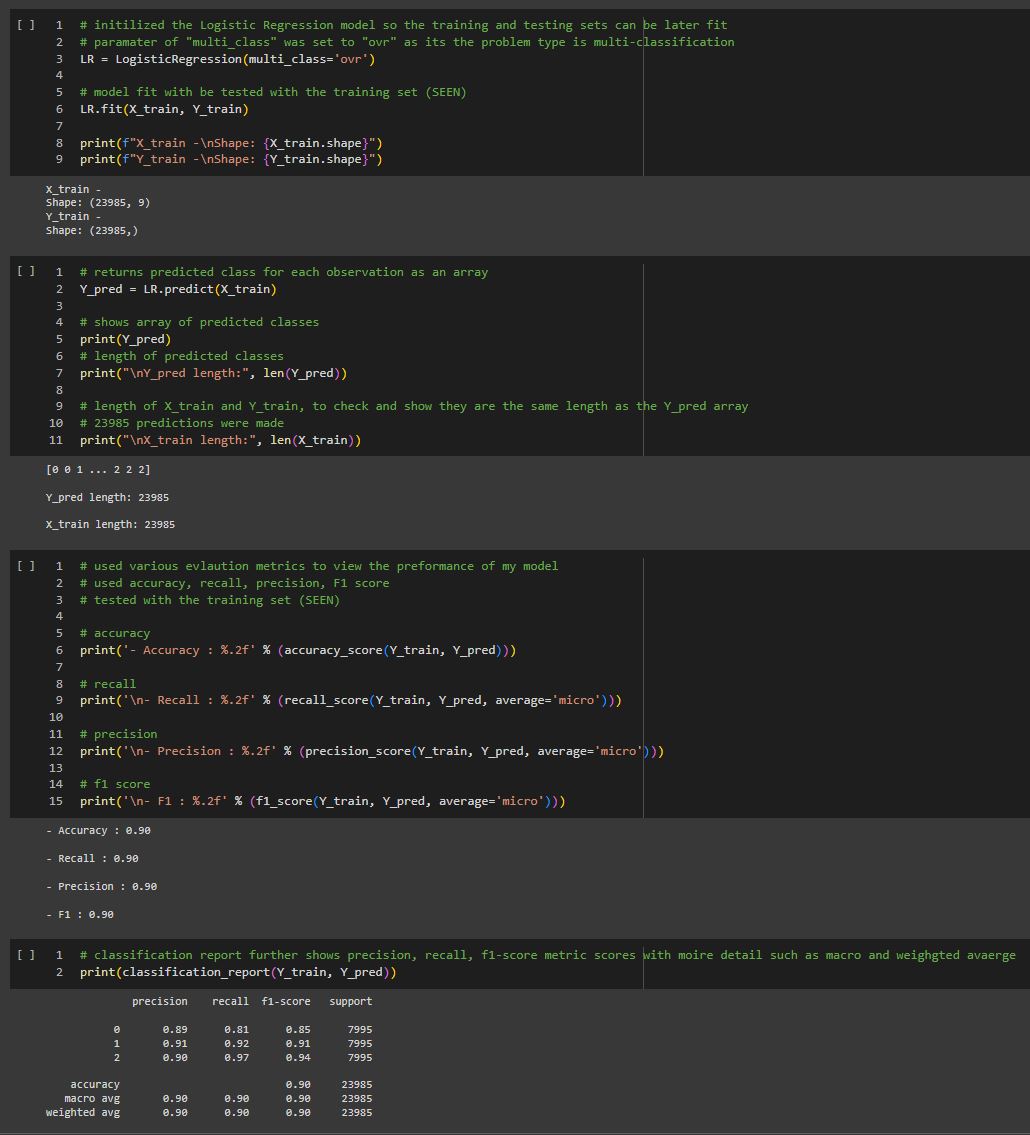
- Algorithm was tested on both SEEN and UNSEEN data.